One thing I really like about the way Microsoft handles their cloud file storage is that the files are pervasive across all the Microsoft devices I have for a given login. When I sign into a PC at home with my personal Microsoft account, all my files are there. Pictures I just took on my phone are automatically synced up to my HP home computer, my Dell tablet, and my personal profile on my work laptop. And that is what is especially cool. Profiles. When my daughter logs into the home PC, she gets here files, not mine. My son was using his laptop at school but when he came home, he can sign into the home computer using the same Microsoft account he used on his laptop and all of his settings and files are there. The Desktop is the same. His files are there. Simple. I love it.
Category Archives: Dad

Do you have a good password?
This is a really cool tool to test how good your password would hold up to a brute-force attack:
![]()
https://www.grc.com/haystack.htm
Also, this sums things up:


Sending information at speeds faster than the speed of light?
I am not a physicist so please excuse my over simplifications of concepts that are undoubtedly very complex and nuanced. However, I have always loved physics and delving into how the world works. What spurs this post is that I’m reading a book by Brian Greene called The Fabric of the Cosmos, Space, Time, and the Texture of Reality, and I’ve had some thoughts come to me around how information might be conveyed at greater than light speed. I’m only in Chapter 4, so perhaps my question will yet be addressed, but I wanted to get my ideas down while they are still fresh.
In his book, Brian Greene talks about the quantum physics concept of particle entanglement, where two particles appears to affect each other instantaneously, despite being at a substantial distance from each other. He uses an analogy where Mulder and Scully are separated by some distance and each have a number of numbered alien cubes which are somehow connected. Opening the door on any cube yields either red or blue inside. So if Mulder opens cube 1 and receives a red result, when Scully opens the same numbered cube, she will receive the same result. This is meant to mimic the particle entanglement to measuring a single attribute of two such entangled particles.
He extends the analogy to explain how a different experiment was done to disprove the EPR theory that every particle has certain attributes even thought they cannot be measured due to the uncertainty principle. In this analogy, Mulder and Scully have cubes with 3 doors, each with red or blue inside. This represent that we can measure a particle’s spin in, say, 3 dimensions (3 doors), as either clockwise (red) or counter-clockwise(blue). If EPR was correct, randomly opening a door at each side would yield greater than 50% of the same result, (red or blue). That is because each cube has a minimum or 2 of the same color, and perhaps all 3. So the other cube is will match 2 out of 3 or better, over a large sample size. In the experiment, this turned out not to be the case, thus showing EPR to be wrong on that account.
However, if I understand the “uncertainty principle” correctly, once Mulder opens one door and it shows red, if he opens the other doors, they should be blank or have no color since only one attribute can be observed. In the case of spin, Brian explains that once you measure one dimension, say the front-to-back, all of the spin motion is conveyed onto that axis. Does that mean that whatever spin is zero for the other dimensions? That to me would be indicated by opening the second or third door on a cube and seeing nothing inside.
Now, given that, if I understand particle entanglement correctly, once one of the two particles has been measured along a specific axis, the other particle will also begin to only spin along that same axis. That would explain why the random sampling of opening doors was less than 50%, since now 2 out of 3 of the checks on the second box would yield neither red nor blue, but nothing (over large sample size).
That all makes sense to me so far. But here is the question: Since this occurs regardless of how far apart particles are, why could this not be used to convey information at speeds greater than the speed of light? In his book, Brian states that the test used to determine if something has traveled faster than the speed of light is whether information has been conveyed. He says that in this case, no information has been conveyed since the results are simple random samplings on each end and are only statistically proving the point. However, why do they have to be random?
To use the Mulder and Scully analogy, suppose Mulder tells Scully to always check the front door on the cube, while he alternates between checking the font door and some other door such that checking the front door indicates he wishes to send a “1” while checking something else indicates he wants to send a “0”. In that way, as Scully continuously checks the front door, she either gets an attribute reading (red or blue) which indicates a “1” or nothing which indicates a “0”. That is, she would see “nothing” due to the uncertainty principle when Mulder opened one of the other doors on his cube thus forcing her cube to only have a red/blue attribute on the door Mulder checked, not the front door which is the one Scully checked. In this way, a message can be encoded by reading the binary values from sequentially ordered pairs of entangled particles. And since it has been experimentally shown that these entanglements and corresponding state changes happen instantaneously, information would thus be traveling faster than the speed of light.
Obviously I’ve missed something that explains why this is not possible. I will continue to read Brian’s books to see what I learn further on this topic. But please chime in if you have the answer (and can explain it in terms I can follow!)
Microsoft Band Battery Experience
When I unboxed my Microsoft Band, it had an 80% charge. I slept with it that night, and it was at 80% in the morning. I threw it on the charger for 30 minutes while I showered, and it was still at 80%. It seems like it really likes 80%!
I wore it that day and slept with it again and it was still looking like the battery was near the top, so I decided not to charge it in the morning while I showered to see how long it would go. I wore it that day, and slept with it again. It stopped recoding my sleep about 3am.
So I put it on a charge at 6am when I got up, and 2 hours later when I checked, it was at 80%. 80% again. I was wondering if it even had 100% as a charge metric. But, 15 minutes later, I finally got to see 100% charge. Now that it is fully charged, I’ll see how long I can wear it before it dies. I suspect that it will 2 full days and nights. But even if it doesn’t, it certainly can handle 1 full day without issue. Not bad at all!
Save your phone from the toilet with Microsoft Band
Admittedly this is probably not a big problem for most people, but if you find that pulling your phone out at inopportune moments has caused you disaster, then the Microsoft Band may be for you. I know someone who accidentally dropped their phone into a flushing toilet! I had a phone slip from its holster, noiselessly through the gap in-between an elevator and the floor, taking a 4 story plunge to its death. Both of these scenarios could have been avoided if our phones were safely tucked away because we could monitor the majority of our communications with Microsoft Band.
I just purchased one so I will be posting about it as I learn how it works. So far, I really like it. Here is my first impressions so far.
Although it looks like a shackle, as Paul Thurrott mentioned in a recent podcast, it fits surprisingly well and is very comfortable. I wore it last night and it provided some very illuminating information about my sleep.
Today, I have been using it to stay on top of my email which has been amazing. I hadn’t realized just how much work it is to take my phone out of its holster or my pocket. That sure sounds lazy! Still, I find I really like doing it that way. Perhaps it will get old. We’ll see.
I also did a couple workouts and it kicked my butt! I would like to see an integration with the service I use at the YMCA which builds workouts which I can print out and follow (e.g. Leg press, 200lbs, 12 reps, rest 60 sec, etc.). The band would be perfect for this. Perhaps that’s what the Golds Gym workouts do as I have not looked at them yet.
So far, I’m very happy I steelhead out the $200. Lets see how I feel about that in a week.
The coolest web forms;
I stumbled upon the coolest web form creator called TypeForm. It users interactive imagery to convey a deeper tie between the form and it’s purpose. One great example is a form asking for ones age could display a birthday cake which changes the candles based on the answer, then blows them out. Very cool. I cann’t wait to try it out. Find it at http://www.typeform.com
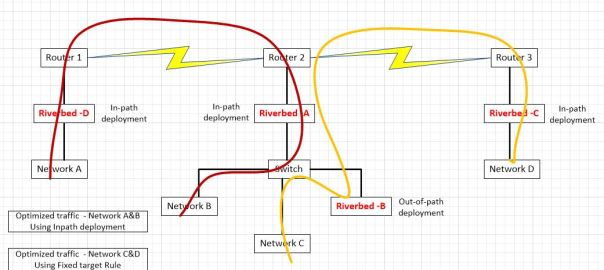
How to pass-through connections on an intermediate Riverbed SteelHead
The Riverbed SteelHeads (SH) is a platform that, simply said, speeds up connections across the wide-area network (WAN). Riverbed solutions improve network performance and thus user satisfaction and productivity, enable storage and server consolidation into the data center by making application performance across the WAN feel like the server or storage is still local in the remote office, and provide a visualization platform for applications needing to remain in the remote office while still being managed centrally, all while lowering ongoing operating expenses by avoiding bandwidth upgrades and requiring fewer managed devices.
One Riverbed customer had a question about how they could integrate two Riverbed optimized networks; one they control (A&B) and another, the do not (C&D). They desired to keep the Riverbeds from each set of networks separate. My response was posted to a technical forum but I also include it here since I found it very interesting. It assumes technical proficiency with the Riverbed SteelHead platform, so unfortunately it will not be appropriate read for those not familiar with the workings of the product.
Using their diagram, let’s take a look at some of the technical requirement around how this would work:
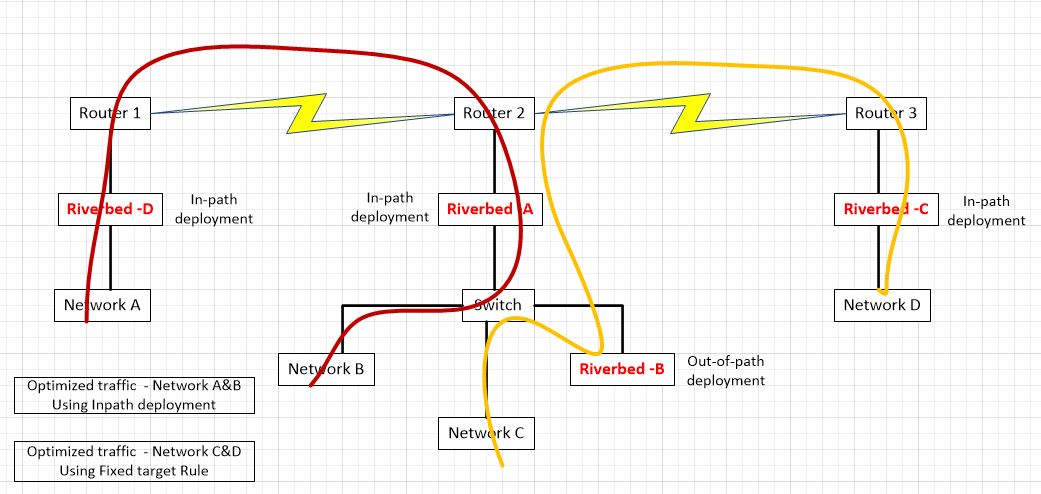
In this scenario, networks A and B are optimizing via auto-discovery by Riverbed A and Riverbed D. Networks C and D are being optimized by a fixed-target rule on Riverbed C pointing to the out-of-path Riverbed B. The question was asked, if we don’t control networks C and D, what needs to be done to ensure that Riverbed A does not participate in optimization between network C and D.
If optimization is indeed occurring between clients on network D and servers on network C via a fixed target rule on Riverbed C pointing to Riverbed B, no peering rule is necessary on Riverbed A to avoid participation in optimization since peering rules are not invoked unless an auto-discovery probe is received. Fixed-Target rules do not initiate such an auto-discovery probe since fixed-target rules hard code the Riverbed to peer with. Furthermore, the optimized connection created by that fixed target rule from Riverbed C to Riverbed B is made on TCP port 7810 which is included in the default pass-through rules on Riverbed A for Riverbed protocols.
However, if we want to make sure that Riverbed C never peers with Riverbed A (due to sizing constraints for example), since both are in-path and may auto-discover each other, we will need both a peering rule and an in-path rule on Riverbed A. Riverbed C may be configured not to perform auto-discovery, but unless we have visibility into its configuration, you can’t be sure.
To handle inbound connections from network D to network C, we would put a peering rule on Riverbed A, matching Riverbed C’s in-path IP address. This ensures that a connection coming from a client on network D to a server on networks B or C would not be optimized. In essence, the peering rule on Riverbed A says to not respond to auto-discovery probes from Riverbed C for any networks behind it. We can also be more selective in the peering rule by using networks’ subnets instead of a peer IP. For example, we could allow connections from clients on network D to be optimized (by Riverbed C and Riverbed A auto-peering) for network B but not network C. We can think of a peering rule as answering the question, “what do I do when I receive an auto-discovery probe from another Riverbed?” If we don’t want optimization from network D to network C, but we do want optimization from network A to network C, the peering rule on Riverbed A would be specific to a peer IP address of Riverbed C. If we don’t want anyone auto-peering with Riverbed A when going to network C, the peering rule would use a destination subnet of network C.
Now, for outbound connections being initiated by clients on network C, due to the way server-side out-of-path works, outbound connections from network C will never be seen by Riverbed B. However, they will be seen by the in-path Riverbed A and thus will receive an auto-discovery probe. Other Riverbeds will respond to that probe and thus cause those connections to be optimized. So, for a connection being initiated on network C going to network D, a probe would be generated by Riverbed A and that probe would then be seen by Riverbed C and they would optimize that connection. Thus, if we don’t want Riverbed A and Riverbed C peering up for connections from network C to network D, we must put an in-path rule on Riverbed A to pass-through connections from network C to network D. If we don’t want Riverbed A optimizing any outbound connections from network C, that in-path rule would just match the source address of network C.
In summary, if we are just trying to keep Riverbed A from peering with Riverbed C, all we need is:
- An in-path rule on Riverbed A passing though connections to network D.
- A peering rule on Riverbed A passing probes from the peer-IP of Riverbed C.
This scenario still allows optimized connections from network A to network C or from network D to network A.
If we are instead trying to prohibit all optimization when networks A or B communicate with networks C or D, it is a little more complex. To do that we need:
- An in-path rule on both Riverbed A and Riverbed D passing through connections to network D
- An in-path rule on Riverbed D passing through connections to network C.
- A peering rule on both Riverbed A and Riverbed D passing through probes from network D.
- A peering rules on Riverbed D passing through probes from network C.
Picture to text in Word
Today, I decided I would just take a picture of our church choir schedule so I would have it on my phone for reference. I remembered that Paul Thurrott on his Windows weekly podcast mentioned that the latest Microsoft Lens app could do Optical Character Recognition (OCR) and put the text and/or the image in OneNote. So I tried it. Wow! It works great!
After opening the app, I snapped a picture. The first cool thing was that it corrected for the angle from which I took the picture so the page looked as if I snapped the picture squarely from the front. I then told it I wanted a word doc and to store the pic in OneNote. I chose to share a link to the doc with a friend and sent it to myself. I opened the .docx file on my windows phone and could see the text converted from the image right above the picture so it was easy to compare to make sure it did it correctly. It did. I love it when technology foes exactly what I want it to do.
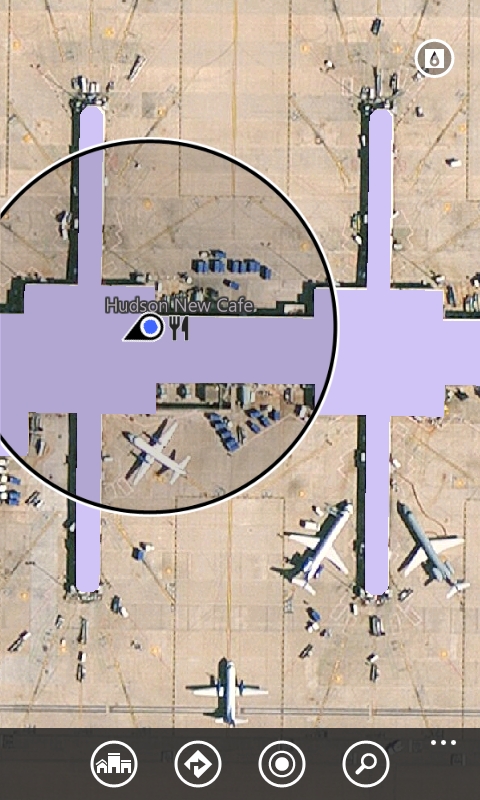
Cortona helped me find dinner in between flights
After getting off of my first flight, I took a look at my windows phone to check on my next flight. I’ve used an app called Flight Status for a long time (upper right corner of image) but noticed that my Cortona tile was also showing me the status of my flight, although I didn’t have to enter the flight info for Cortona to do that.
I tapped on the time to see what else she could tell me and saw a link to a terminal map.
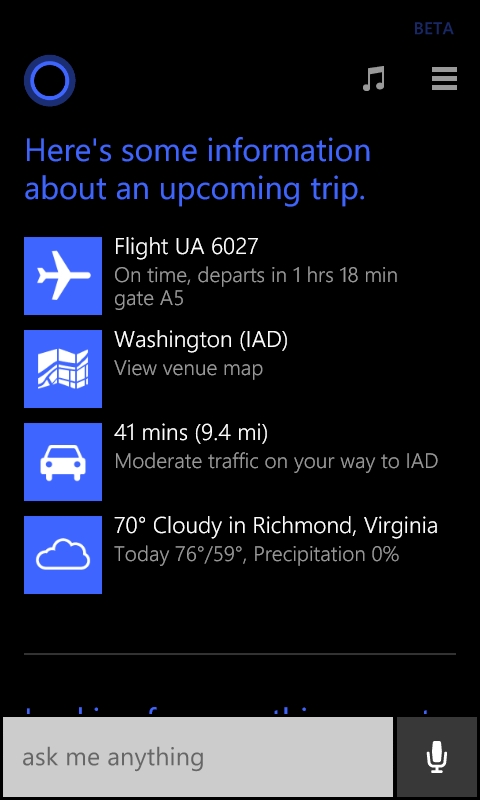
I clicked on it and she showed me a map of the terminal including restaurants which was perfect because I was hungry!
Hot food
Have you ever eaten something that was really hot but you didn’t realize it until it was in your mouth? What I find myself doing is trying to keep it off my tongue by holding it between my teeth. I then breath in through my nose and out through my mouth in an attempt to cool the food. It occurred to me that in doing that, I am trying to cool food down using air that is close to 100 degrees, or 98.6. Or perhaps, the air is cooler not having been in my lungs for long. In any case it always seems to work! Then I wondered if there was a better way to do it, which of course there is. Don’t eat really hot food!